Alignment on Microservices
At travel audience we are working on a fast evolving system where multiple teams are regularly introducing new services. The word “microservices” is often used, but it appears people often have different opinions about what that term actually means.

Are microservices simply great? Should we always have more of them? What are the trade-offs involved? How do we decide on the way of splitting certain functionality across services? If you often need to answer these questions, this article can help you to better communicate when the microservices topic comes up. And hopefully it will help us all to make more informed decisions when we are evolving our systems.
About the term “microservices”
As you have undoubtedly already experienced, the term “microservices” is quite confusing. It is unclear what granularity of services the “micro” part in the name is referring to. How are they different from the Service-Oriented Architecture (SOA)? In my opinion, there is no point in trying to clarify this distinction. As we will see later, granularity is not defined by a perfect choice of a desired size, but instead by the requirements of the business domain, separation of concerns, cohesion and coupling, and all other software design forces.
It is useful to make a quick analogy to the size of a method. How do you choose the length of a particular method? By the number of lines of code — should it be exactly 5 lines, or not more than 10, or 20, or 50? No. To simplify it a bit, you choose the size of the method so that all the operations in the method are on the same abstraction level. Multiple operations that implement lower-level functionality are grouped together into a single higher-level operation by means of extracting functions/methods. There is a similarity to choosing the size of a service — you want to have cohesive domain with well defined boundaries that can evolve or scale independently of the other parts of the system. The size is only an indirect concern brought in via other design forces.
I’ll try to use the term “services” from here on.
Trade-offs of breaking down services
Breaking down a service into smaller ones comes with a complex set of trade-offs. Let’s quickly list a few:
- Independent evolution but release coordination
- Independent releases but deployment complexity
- monitoring maturity required
- logging more critical - Simple service domain but complex service interactions
- easier testing of a service but harder testing of cross-service functionality
- easier debugging of a services but harder debugging across services
- simple design of a service but complex architecture - Better scaling control but more communication latency
- Well defined API boundaries but less expressiveness (type safety) between domains
- Enables different choices of technology and languages but less sharing and more duplication of effort
- Better encapsulation of state but harder to share the state
- More availability but less consistency
- no single point of failure but no single source of truth - Better isolation of concerns but bigger cost of getting the separation of concerns wrong
- great domain encapsulation but costly to redefine boundaries - … and more
Note that this isn’t a perfect categorization by any means, nor an exhaustive list of all the trade-offs involved; but hopefully it shows that deciding on when to split a service into multiple services is an involved and complex decision.
There are potential benefits from breaking down services into smaller parts — assuming we get the breakdown of the individual parts right! But if we get responsibilities and domain modeling wrong, we lose most of the benefits while still paying all the costs!
So, is having more services better or worse? Neither! It really needs to be evaluated on a case-by-case basis. It is an architectural tool that can be applied to some situations for great benefits, but it’s harmful in others. Not everything is a nail, and we don’t have only hammers.
Getting the design right
It is useful to keep in mind that it is generally easier to deal with monoliths/bigger services than it is with microservices. Particularly when we don’t know the domain and are first time working on something. So one strategy that works reasonably well is to start with bigger chunks and break them down as we learn more about the domain. This does not mean that we need to keep bigger services for long, it can be that we have them only while a new system takes a bit of shape. We can split them as soon as we are confident we can get the domain boundary right.
Monolith and Microservices on a spectrum
We are often talking about microservices as opposed to monoliths. But that distinction is a bit faulty. The Terrible Monolith is just one end of the spectrum, as is The Microservice Hell. Let’s try to have a more fine-grained view on this spectrum. The main topic we are taking a look at is the separation of concerns.
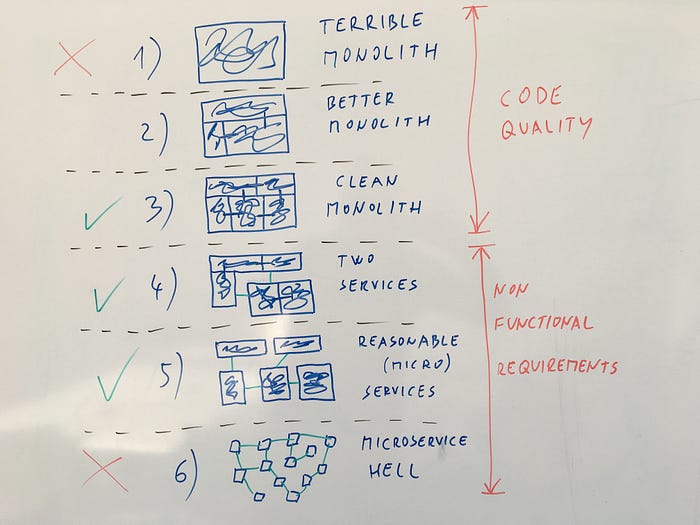
It is useful to consider six different states of the system at this spectrum. Let’s list them in the typical order of evolution:
- Terrible Monolith: the messy system with bad design, mixed concerns, low cohesion, arbitrary and hard to understand coupling
- Better Monolith: some domain modeling, introducing separation of concerns, better cohesion, less coupling
- Clean Monolith: well designed monolithic system, clear domain modeling, separation of concerns; maximized cohesion, minimized coupling
- Two Services: Clean monolith split into two services on already well defined domain boundaries
- Reasonable (Micro)Services: Clean Monolith split into different services to enable: separate evolution, scaling, optimization, smaller domains, etc.
- Microservice Hell: microservices with ill-chosen boundaries, strong coupling between microservices that share common concerns, impossible to evolve them separately, almost impossible API evolution, infrastructure overhead, need for coordinated deployment, etc.
Dominant concerns
It is useful to consider what are the dominant concerns at different segments of the spectrum. Let’s examine two separate ares:
1) Going to stage 3 (Clean Monolith) is primarily about code quality.
- Up to this stage we are cleaning up the code, defining cohesive domain boundaries, clarifying the dependencies, introducing interfaces and abstractions, etc.
2) Transition to stage 4 (Two Services) and further is mainly about enabling non-functional requirements.
- With stage 4 we have started to split the system down to multiple services to enable different resource requirements, different scaling profiles, to solve latency issues with caches, etc.
Note that those are just dominant concerns, not the only ones. For example, we still care about abstraction in all the steps. Particularly reuse can be a reason to split system to services.
Scaling and service granularity
Scaling is a concern that often triggers splitting up services and so it’s worth exploring it a bit more. For simplicity let’s assume there are only two endpoints in the service at hand. We can think of splitting them up into separate services based on two topics:
- Different traffic profiles in time. For example, one endpoint is used directly by active users and thus depends on the time of the day, while the other is active only during the nightly batch processing.
- Different resource needs. For example, one endpoint is memory-bound while the other is CPU-bound.
The first topic, changes in traffic over time, is interesting to consider from provisioning/scaling needs. Contrary to the intuition, it is sometimes easier to scale horizontally (more VMs/containers) bigger services, particularly with unpredictable traffic loads. This happens when different endpoints don’t change the traffic load in sync. The traffic spikes will affect only some endpoints and will eat up only a part of the total over-provisioning buffer. This of course comes with a trade-off — in this case a drastic overload in one endpoint could have negative impact on the others that are not undergoing increased load.
The second topic, different resources needs, is relevant when:
a) Resource needs scale differently with the traffic, e.g. you need more memory more aggressively than processing power.
b) Underlying infrastructure is cheaper when trying to get only one dominant resource. This happens because cloud providers often have machines optimized for a particular resource, e.g. for compute power or for available memory.
Cost and service granularity
Are microservices cheaper or more expensive than monoliths? It depends on the details of a given situation. As mentioned above, with smaller services you can potentially save money on scaling. At the same time you often need additional infrastructure (e.g. queues) for inter-services communication, while in a bigger service this mostly happens in-process, often without incurring additional costs.
Challenges of distributed systems
The more services are present in the system, the harder it is to reason about consistency. Particularly about consistency in failure scenarios, and those increasingly become the norm as the system grows. This turns out to be a significantly more complex topic than people generally assume.
To just scratch the surface, there is:
- CAP theorem — and so you generally can’t get Consistency and Availability at the same time
- The Eight Fallacies of Distributed Computing — and it’s easy to implicitly assume one of them at some point without even realizing it
- Two Generals’ Problem — and so there is no such thing as a “full fail-over” and you must be able to deal with partial failures
- and then Jepsen just for the scary “fun” — your favorite database, queue, system is likely in there…
This does not mean that you should not have more services or bigger systems. But it does mean that you need to be able to deal with this complexity and that you are more likely to make costly mistakes along the way.
Reuse: libraries vs. services
It is useful to quickly explore libraries vs services. Both enable reuse, but in a different way:
- updating libraries requires less client coordination then services
- but you will have more versions used in parallel - libraries are specific to a given language while service reuse depends only on API protocols
- library API is more expressive, but they bring dependencies management problems with them - services generally deal more with run-time/process concerns and exist continuously in time
- while libraries are more artifacts that are created and published at discrete points in time
- libraries generally don’t have persisted state while services can have state shared over time across versions/deployments
You can and generally should use both tools. Which approach is better will depend on a particular problem at hand.
Teams: ownership, boundaries, communication
Another significant matter to explore on this topic is the human one: software artifacts are created in human “systems”. The design of a technical system is always influenced by the organizational setup, in which the system is living in. Some of relevant concerns are:
- ownership
- knowledge sharing
- bus factor
- organizational structure and information flow
- Convey’s law
Conclusion
Should you, and to what extent, use microservices? As with most technical topics, the trade-offs do matter! Your particular situation and context matter! Microservices are at the same time both “good” and “bad”, “useful” and “dangerous”, “beautiful” and “terrible”.
Unfortunately, microservices are not the proverbial silver bullet, but simply another useful tool in your design arsenal. It is my belief that the best way to tackle the topic of microservices is by starting to build understanding of the trade-offs involved. And to communicate a lot with your colleagues.
I hope that this article gives you a basis for further exploration and for a successful application of this powerful architectural tool.

